LLM Agents Need Action-Conditioned World Models
Status: draft product and research framing for why LLM tool-calling agents are a strong baseline, but not the whole architecture for digital operations.
Collaboration
If this direction resonates with you, I would be happy to talk with like-minded people, collaborate on research, and work on use-cases together.
Ideas are not the bottleneck. Hands are. Time-series modeling should be moving at least as fast as vision, audio, and robotics.
- Email: [email protected]
- X: @chemeris
- Telegram: @alexanderchemeris
Purpose
Central thesis:
LLM agents are planners and operators, not dynamics models.
They can inspect, explain, and propose actions.
They should not be the component that continuously scores what each
candidate action will do to telemetry, risk, cost, and recovery.
That is the job of an action-conditioned world model.LLM agents such as Codex, Claude Code, and similar tool-calling systems are strong reasoning and execution layers. They can read code, inspect logs, run commands, write patches, and explain their plan to a human operator.
That makes them the right baseline for Kubernetes OTEL Control Gym, not an opponent to dismiss. The important question is narrower:
Is a general LLM agent enough for digital operations,
or does it need a lower-level action-conditioned world model?This page argues for the second answer. LLM agents can be excellent upper-level planners, but a reliable digital-operations agent also needs a telemetry-native layer that predicts what happens after candidate actions.
Core Distinction
The useful split is:
LLM agent:
inspect, reason, explain, plan, call tools
action-conditioned world model:
predict what happens if action X is applied now
controlled gym:
generate trajectories and evaluate decisionsIn other words:
Codex / Claude = reasoning and tool-use layer
action-conditioned world model = learned dynamics layer
k8s-otel-control-gym = evidence generator and evaluatorThe target is not to replace LLM agents. The target is to give them a better substrate for choosing actions.
Why LLM Agents Are Strong Baselines
An LLM agent is a serious baseline because it can already perform many parts of an SRE workflow:
- read source code, documentation, runbooks, incident notes, and configuration;
- inspect logs, traces, metrics summaries, and alerts through tools;
- form root-cause hypotheses;
- run diagnostic commands;
- propose and apply code or configuration changes;
- iterate when an experiment fails;
- explain its reasoning to a human operator.
For many incidents, this is already useful. If a failure is caused by a known bad deploy, an obvious configuration error, a broken dependency, or a documented runbook step, a tool-using LLM may solve the problem without a specialized world model.
That is why LLM agents should be benchmarked on the same stand. If Codex or Claude is enough for the first controlled tasks, that is valuable evidence.
Agentic Automata Learning adds a stricter warning to this baseline framing. In a deterministic hidden-DFA environment with exact membership and equivalence-query feedback, LLM agents still lose efficiency and robustness against classical symbolic learners, and their traces accumulate non-informative queries. This is not evidence that learned neural world models already outperform LLM agents; the paper does not evaluate Dreamer-style, JEPA-style, CWM/Genie-like, or telemetry-native action-conditioned dynamics models. Its value is narrower: it shows that an LLM-only prompt loop is a weak mechanism for reliable model inference, so the benchmark should measure query quality, evidence reuse, and inferred-state consistency, not only final task success.
Code World Model Evidence
CWM is the closest public source so far for the claim that LLM agents can benefit from action-observation training in a digital environment. It treats Python source lines, shell commands, and file edits as actions, and local variables, command output, tests, files, and repository state as observations.
That makes CWM directly relevant to this page, but it also sharpens the boundary. CWM is a code and computational-environment world model; it is not a telemetry-native operations world model. Code execution is usually more discrete, more inspectable, and more test-verifiable than production operations. An SRE world model still needs numeric telemetry, graph time series, event streams, deployment state, action timing, failed-action status, rewards, and human-approval semantics.
The useful transfer is therefore architectural:
CWM-style layer:
code/repo state + tool action -> computational environment response
OTEL control layer:
telemetry/graph state + operator action -> future telemetry/reward/riskThe hybrid system should let an LLM reason about code and propose actions while a telemetry-native action-conditioned world model scores operational consequences.
Digital World Model Evidence
Agentic World Modeling gives a broader survey frame for the same direction. It defines a digital-world regime where transitions are governed by software laws: API contracts, UI state machines, file-system logic, permissions, type constraints, error branches, and network protocols. Representative systems include web-agent simulators, GUI world models, renderable-code world models, and LLM/RL digital simulators.
That supports the local thesis, but with an important boundary. Web, GUI, code, and game world models are digital world models because their states and actions are software-defined and often verifiable. An SRE world model is a stricter sibling, not a solved case:
web / GUI world model:
DOM, screen, files, code, permissions + action -> next digital state
operations world model:
telemetry, logs, traces, service graph, events + operator action
-> future telemetry, risk, reward, recovery stateThe article’s useful contribution here is the diagnostic vocabulary: a model should not be called decision-usable merely because it predicts the next screen, token, or trace. It should preserve long-horizon coherence, respond to interventions, and respect the governing constraints of the digital environment.
Where LLM Agents Are Not Enough
1. They Do Not Have A Learned Dynamics Model Of The System
An LLM agent can reason that a rollback, restart, scale-up, or traffic shift might help. But this is usually language-level reasoning from code, logs, documentation, and general experience.
A digital operations system needs a more specific interface:
observation_history + service_graph + candidate_action
-> predicted_next_observation
-> predicted_reward
-> risk / uncertainty
-> action rankingThe missing object is not another explanation. It is a learned model of how this class of systems changes under actions, control inputs, and interventions.
2. Production Gives One Timeline, Not Counterfactuals
In production, after an operator chooses one action, only one future is observed:
state S + rollback -> observed futureThe operator does not observe what would have happened under other choices:
state S + scale up -> unobserved future
state S + wait -> unobserved future
state S + traffic shift -> unobserved future
state S + escalate to human -> unobserved futureAn LLM agent can discuss these alternatives during a real incident, but it cannot ask production to replay the same incident with several different actions. Ordinary production logs contain only the action that actually happened and the future that followed.
3. Telemetry Is Not Naturally A Text Problem
Operational telemetry is dense, high-dimensional, and temporal. A single service or server can expose hundreds of numeric channels or variates, and a real system multiplies that by services, hosts, edges, regions, time buckets, logs, traces, events, workload changes, and delayed effects.
The main issue is therefore not only that telemetry is “not text.” It is that the raw signal can exceed an LLM context window very quickly. Even if it fits, dumping thousands of time-channel values into a prompt is usually the wrong interface: it spends context on low-level samples, loses temporal resolution through summarization, and makes cross-service coupling hard to preserve.
An LLM agent usually sees this through a textual compression layer:
raw telemetry -> summary -> prompt -> answerThat can work for diagnosis, but it can also lose the signal that matters for control: timing, magnitude, cross-service coupling, delayed response, and small changes that predict a later failure.
Scaling Test-Time Compute for Agentic Coding supports the first half of this claim. In agentic coding, full action-observation rollouts are too long and noisy for reliable selection or reuse, while compact structured summaries work better. The operations analogue is not “avoid summaries.” It is “make summaries a trained, tested state interface.” The compression layer must be accountable for preserving action-relevant facts.
An action-conditioned world model for operations should be telemetry-native:
node_features + edge_features + events + actions + rewardsThe LLM can still sit above that model and ask questions, choose candidates, and explain decisions.
4. LLM Agents Are Expensive Inner-Loop Simulators
To choose an operational action, a controller may need to compare many candidates:
do nothing
wait 5 minutes
scale checkout from 2 to 5 replicas
restart cart
rollback recommendation
increase CPU limit for payment
shift 20% traffic to the previous version
escalate to humanThe timing budget is tight. Operational metrics commonly update every few seconds, often in the 1-60 second range depending on scrape interval, aggregation, and alerting pipeline. A controller may need to refresh state, score candidates, and decide whether to wait, act, or escalate within that cadence. A large tool-calling LLM can be valuable at a higher level, but it is usually too slow and variable to run as the inner-loop simulator on every telemetry tick.
Using a large LLM to simulate each candidate future is therefore slow, expensive, and hard to calibrate. A learned action-conditioned world model can be the cheap inner loop:
candidate actions -> predicted futures -> ranked actionsThe LLM can remain the outer loop that proposes candidates, interprets surprising states, and communicates with humans.
5. Goal-Following Can Be Unsafe
Tool-calling agents are often trained and prompted to make progress toward a goal. In operations, this can be dangerous. Sometimes the correct action is not to keep calling tools or trying fixes.
The action space must include:
NOOP
WAIT
COLLECT_MORE_EVIDENCE
ESCALATE_TO_HUMANThese are not failures to act. They are valid control actions.
A useful operations agent should learn when acting is worse than stopping. The benchmark should therefore reward correct escalation and penalize harmful persistence.
What The Action-Conditioned World Model Adds
For digital operations, the action-conditioned world model acts as an action-consequence layer. It does not need to read every source file or produce a beautiful explanation. Its job is narrower:
history + graph + candidate action
-> future telemetry distribution
-> reward / risk estimate
-> uncertaintyThat gives a planner the missing primitive:
What will happen if we do this?This also changes the meaning of observability data. Metrics, logs, traces, and events are no longer only evidence for root-cause analysis. They become observations in controlled trajectories:
state/action/next_state/reward/labelA Hybrid Architecture
The practical architecture is likely hybrid:
LLM planner
-> reads code, docs, runbooks, incident context
-> proposes candidate actions and safety questions
action-conditioned world model
-> evaluates candidate actions against telemetry and graph state
-> predicts future telemetry, reward, risk, and uncertainty
safety policy
-> blocks unsafe actions
-> chooses WAIT / NOOP / ESCALATE when appropriate
executor
-> applies the selected action through Kubernetes, feature flags, traffic control, or a human approval flow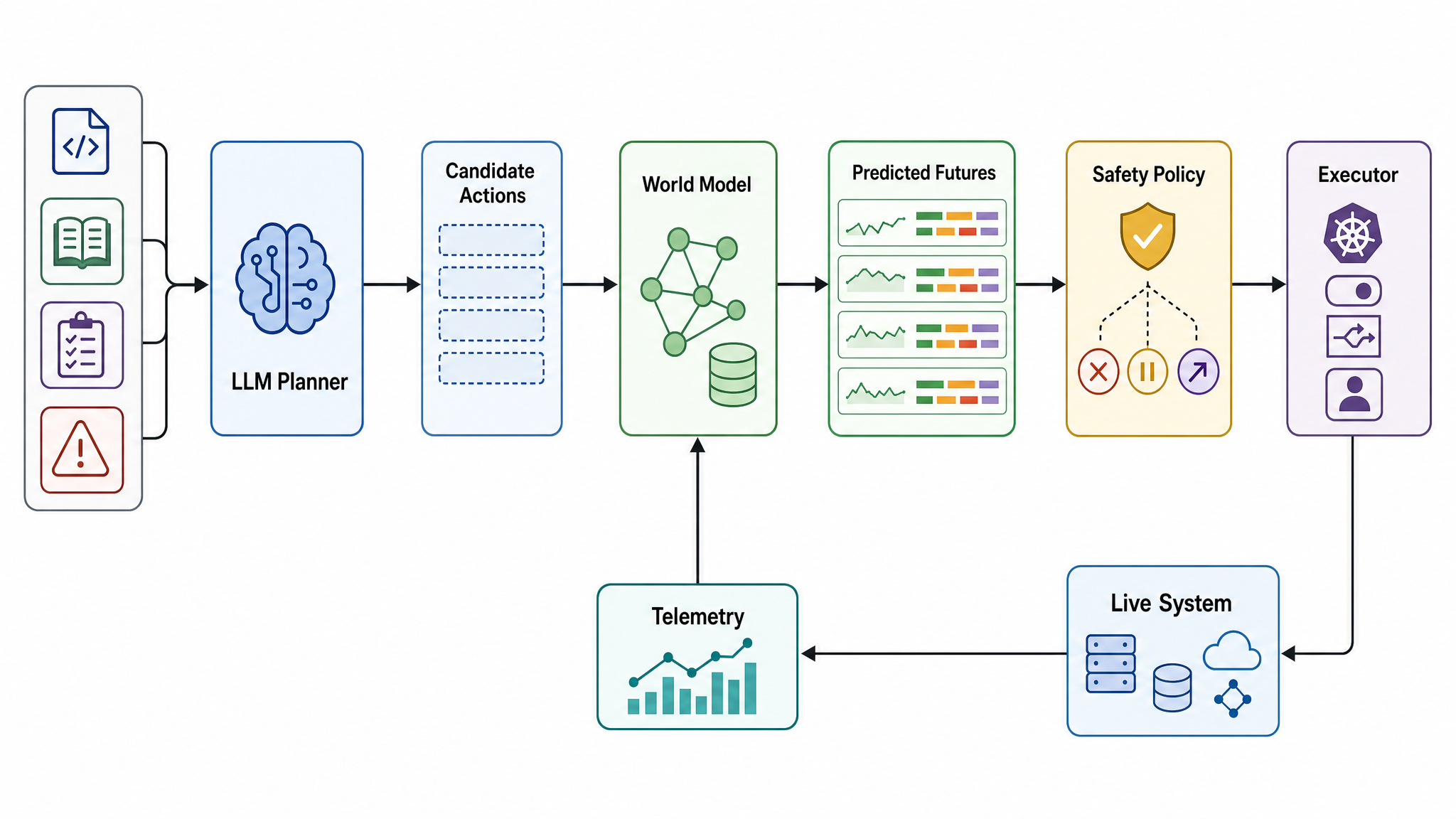
The LLM is still valuable. It is just not asked to be the whole control system.
Benchmark Design
OTEL Control Minimal Demo should treat LLM agents as first-class baselines, not as an afterthought.
Useful baselines:
| Baseline | Interface | What It Tests |
|---|---|---|
| Passive forecaster | history -> future | Whether action information is needed at all. |
| Scripted SRE policy | state -> fixed rule action | Whether simple runbook logic is enough. |
| Codex / Claude agent | telemetry summary + tools + prompt -> action | Whether general tool-using reasoning is enough. |
| Action-conditioned world model | history + graph + candidate_action -> future/reward | Whether explicit action conditioning improves intervention ranking. |
| Hybrid LLM + action-conditioned world model | LLM proposes, world model scores, safety policy gates | Whether the layers complement each other. |
Core metrics:
- action-ranking accuracy against the best scripted or measured intervention;
- regret relative to the best available action;
- closed-loop reward through
step(action, dt); - recovery time;
- SLO restoration probability;
- cost and blast-radius penalty;
- safety penalty for harmful tool use;
- correct
WAIT,NOOP, orESCALATE_TO_HUMANrate; - action-ablation degradation when action fields are dropped, masked, or shuffled.
The key result to seek is not:
The specialized model beats Codex on every task.The useful result is:
Explicit action-conditioned modeling improves intervention ranking,
safety, or cost under scenarios where actions materially change the future.Relation To Foundation TSFM Agenda
This is an idea page, so the verdicts below describe the intended contribution if the proposed system or experiment works. Evidence status is recorded separately in the Evidence and Missing pieces columns.
The page contributes to the digital-world robot north star by separating the LLM reasoning layer from the time-series action-conditioned world-model layer. The table maps that contribution to concrete agenda slots.
| Agenda slot | Verdict | Evidence | Missing pieces |
|---|---|---|---|
| Causal structure, counterfactuals, and control | partially closes | Proposes explicit comparison between LLM-agent decisions and action-conditioned next-state/reward models. If validated, the lower layer would estimate consequences of typed DevOps actions, including WAIT, NOOP, and ESCALATE_TO_HUMAN. | Implement the gym baselines and show that action-conditioned scoring improves intervention ranking, regret, safety, or cost on controlled scenarios. |
| Benchmarks: what level of modeling is tested? | partially closes | Proposes Codex/Claude, passive forecaster, scripted SRE policy, action-conditioned world model, and hybrid controller baselines under the same observe -> action -> next observation -> reward loop. | Publish benchmark tasks, prompts, policies, metrics, and failure cases. |
| Context interface | partially closes | Treats code, docs, runbooks, graph state, telemetry, action history, and intervention capabilities as separate context surfaces for different layers. | Stabilize a schema that decides what goes to the LLM planner, the telemetry-native model, and the executor. |
| Compression interface | adjacent | Agentic coding evidence shows structured summaries can beat raw traces for long-horizon reuse. | Define telemetry summaries that preserve timing, magnitude, topology, action status, and uncertainty rather than only natural-language gist. |
| Safety and operational constraints | warning | Makes harmful goal persistence a first-class failure mode and treats stopping or escalating as valid actions. | Define controlled scenarios where acting is worse than waiting or escalating, and score agents on correct refusal or handoff. |
Open Questions
- Which telemetry summaries give LLM agents a fair baseline without hiding action-relevant signal?
- Should the LLM propose candidate actions first, or should the action-conditioned world model score a fixed action catalogue?
- How should uncertainty from the action-conditioned world-model layer be communicated to the LLM planner and the human operator?
- What is the minimum scenario set where Codex/Claude, scripted policy, passive forecasting, and action-conditioned scoring separate cleanly?
- How should
WAIT,NOOP,COLLECT_MORE_EVIDENCE, andESCALATE_TO_HUMANbe rewarded? - When should the system prefer a deterministic runbook over learned action ranking?
- Which failures should block tool calling entirely rather than ask the model to continue reasoning?